
A Deep Dive into AI Inference Platforms - Part 3
Modeling Real-World AI Inference Costs and How Companies Should Choose Platforms

In Part One, I explored the core categories of AI inference platforms. In Part Two, I analyzed how customer demand and provider competition shape market evolution. In this final part, I focus on the ultimate test: how do these platforms perform in real-world workloads, and what should companies consider when choosing—and expect to pay—at scale?
A Modeling Exercise: What Does 20 Million Tokens Really Cost?
To ground this discussion, I’ve modeled a representative benchmark workload: 20 million tokens of inference. That’s roughly equivalent to handling 10,000 user queries with 2,000-token responses each, or powering a large-scale summarization, RAG, or embedding pipeline. It represents a scale that is common for startups moving from experimentation into early production, or for larger teams conducting pre-production benchmarking.
The goal of this analysis is not to crown a “cheapest” winner. Rather, it’s to illustrate how platform type, model architecture, latency requirements, and optimization strategy all intersect to define the true economics of AI deployment at scale.
The table below presents our current snapshot as of May 2025, showing how different providers and platform types would price this job. The figures are intended to serve as directional benchmarks across providers, not hard predictions of any specific bill.
Cost Comparison of 20M Token Inference Jobs Across AI Platform Types (May 2025 - Link to the Google Sheet )

Why API Token Prices Vary
While API costs are simple to calculate, the actual price per token varies heavily depending on business model, infrastructure, and workload pattern:
Model IP & Size: Frontier proprietary models like GPT-4.5 or Claude 3 Opus charge premium rates (to recoup model R&D costs), while open-source models like LLaMA 3 or Mixtral have drastically lower token prices.
Batching & Throughput: In managed APIs, behind the scenes, providers run their own batching + optimization. For large batch jobs (e.g. document pipelines), cost-per-token is lower. For real-time requests (e.g. chatbots with small input/output), the same provider incurs higher internal compute cost per token.
Platform Overhead: Proprietary APIs bundle extra services (SLAs, customer support, security/compliance), leading to much higher markups over raw compute costs. Managed APIs like Together.ai and Fireworks have lower markups but also fewer enterprise features.
Latency Requirements: Low-latency real-time inference consumes more GPU time per token, raising the effective cost-per-token vs. batch jobs that maximize throughput.
Autoscaling & Monitoring: Some API providers charge hidden fees (or have implicit markups) for orchestration, autoscaling, and observability features built into the API.
In other words: the price is heavily shaped by technical, operational, and business factors behind the scenes. The best approach is to measure it empirically. If it’s a batch job, 20M tokens might take just a few minutes. If it’s real-time at 60 tok/sec, it’s a totally different story. With that in mind, the runtime and cost estimates in the next section should be viewed as directional benchmarks, not absolute truths. They’re built on throughput and GPU utilization assumptions (e.g. 1–2M tokens/hour for large LLMs), and aim to help compare relative cost profiles across providers—not predict your exact bill.
In production? Always benchmark on your actual stack.
Cost Formulas for AI Inference
To give a sense of how these costs are determined in practice, we can break down the two main pricing approaches: DIY GPU rental and API token pricing.
DIY GPU Platform (hour-based)
The economics of DIY GPU hosting is a straightforward function of resource time and efficiency:

Where:
•GPU Hourly Rate = hourly price of the rented GPU (e.g., $1.99/hr for RunPod H100)
•Throughput = average number of tokens processed per second (heavily model and batch size dependent)
•GPU Utilization = how effectively the GPU is used (e.g., 0.8 = 80% utilization)
•3600 = number of seconds per hour
This simple formula highlights how optimization strategies like batching, speculative decoding, and quantization can directly reduce the cost of GPU-based inference.
Managed API Platform (token-based)
At first glance, API pricing appears more predictable:
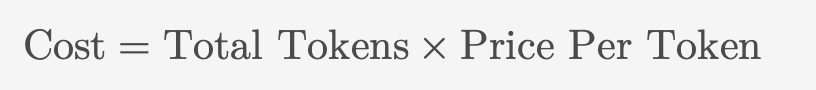
However, in reality, Price Per Token is not a pure technical number—it is a composite of both enterprise needs and platform-level business decisions. It can be thought of as:
Total Price Per Token = Base Cost + IP Markup + Infrastructure Cost + Batch/Latency Penalty
Where:
•Base Model Cost reflects the compute cost for serving that model (lowest for open-source models like LLaMA-3, higher for frontier models like GPT-4o).
•R&D / IP Markup is added by proprietary model providers to recover development and training investment.
•Platform Overhead accounts for features like autoscaling, orchestration, fine-tuning pipelines, and SLAs.
•Latency / Batch Penalty represents the inefficiency of serving small requests or latency-sensitive applications where batching can’t be maximized.
Importantly, these extra layers reflect strategic choices by providers:
•Enterprise customers may accept premium rates in exchange for reliability, compliance, and customer support.
•Startups or researchers may optimize batch size and latency tolerance to minimize per-token spend.
How Companies Choose—and Should Choose—AI Inference Platforms as Their AI Maturity Evolves
The choice of inference platform in my opinion, what matters most is AI operational maturity: how far a company has progressed from experimentation to scaled deployment. Startups and established enterprises alike follow a remarkably similar path, driven by cost, flexibility, and control at each phase of AI adoption.
As discussed earlier, now see three dominant categories of infrastructure: Proprietary APIs (OpenAI, Anthropic, Google); Managed Open-Source APIs (Together, Fireworks, Replicate); and DIY GPU Infrastructure (RunPod, Lambda Labs, Modal). The way organizations move through these categories—and how fast they move—is defined by whether they are AI-native or traditional companies adopting AI for the first time. Across both AI-native startups and traditional enterprises, the same pattern holds:
1.Proprietary APIs for experimentation and speed
2.Managed APIs for scaling cost-efficiently without full infra ops
3.DIY GPU hosting for large scale, privacy, or specialized workloads
The difference is only in how fast companies move across the stages. Startups may go through all three within a year. Enterprises may spend 12–24 months at each stage. But no company—regardless of size or stage—can afford to ignore inference costs as they scale.
AI-Native Startups: From Prototype to Scale
AI-native companies, especially those founded in the post-ChatGPT era, often start directly with Proprietary APIs. OpenAI’s GPT-4o or Anthropic’s Claude 3 offer unbeatable out-of-the-box accuracy and latency for launching experiments fast. For a founding team with no infra engineers, shipping a product can be as simple as calling an endpoint. Time-to-market is everything, and paying premium token rates is acceptable when you have no scale.
But AI-native startups scale in ways traditional SaaS never did. LLM-driven companies can go from prototype to 100x customer usage in under 6 months. At that point, many teams face “inference shock”: they realize their infrastructure costs are growing linearly with their user base—and that staying on proprietary APIs would lead to unsustainable burn. For some, $100K+ monthly API bills arrive within weeks.
The fastest-growing companies rapidly transition to Managed Open-Source APIs. Together.ai, Fireworks.ai, and others let startups switch to LLaMA, Mistral, or Mixtral models at up to 10x lower token costs. Managed APIs still offer simplicity—an endpoint and autoscaling without GPU management—but unlock control over which models run, decoding parameters, and batching strategies.
For the fastest scaling startups (think AI agents, copilots, and workflow automation platforms), even Managed APIs eventually hit cost ceilings. That’s when the some mature AI-native teams graduate to DIY GPU Infrastructure, renting raw compute from RunPod, Lambda Labs, or Modal. With in-house fine-tuning, optimized batching, and hardware control, companies can cut costs by another 5–10x. But this requires strong MLOps discipline: orchestration, autoscaling, failure recovery, and caching must be built internally.
Established Enterprises: Experiment → Pilot → Cost-Optimize
Established companies or late-stage startups follow a similar journey, but at a different pace and with different risk tolerance. An enterprise retailer, bank, or healthcare company experimenting with generative AI in 2024–2025 often starts by running proofs-of-concept using Proprietary APIs.
These APIs are ideal for early-stage AI teams who want to test ideas with zero infrastructure risk or legal exposure. They simply need to validate use cases with real data. Once experiments turn into pilot deployments (internal chatbots, document summarization, RAG search engines), cost and compliance concerns surface. These companies typically transition to Managed Open-Source APIs for more predictable economics and optionality to host models in a private cloud or VPC setup. The flexibility to choose between open-source model families without fully managing GPU clusters allows large companies to meet internal governance standards while scaling workloads safely.
For enterprises with long-term, production-critical AI systems—and especially for companies with strict privacy, data residency, or regulatory constraints—some move to DIY GPU Infrastructure. These companies often choose to deploy LLaMA or Mistral models in fully isolated private clouds, via bare-metal GPU rentals or on-prem clusters. The control and cost savings are critical for business-critical workloads, even if the operational overhead is high.
This concludes our three-part series on this topic. Inference is no longer just a technical choice—it has become a fundamental driver of AI business economics.