
A Deep Dive into AI Inference Platforms - Part 1
A Technical and Economic Guide to 3 Types of Inference Platforms

As AI models become increasingly sophisticated, the industry’s focus has shifted from the resource-intensive task of training to the pivotal stage of inference—deploying models to deliver real-time predictions and insights. Inference has become the cornerstone of AI adoption, powering applications like chatbots, fraud detection systems, and autonomous vehicles. However, achieving low-latency, cost-effective, and scalable inference at production scale presents formidable challenges. Infrastructure must adapt to unpredictable demand while ensuring instant responses and manageable costs. Specialized hardware—such as GPUs and TPUs—provides the raw compute power required for these workloads, while software techniques like quantization and pruning are essential to optimize efficiency without compromising accuracy. The rapid rise of high-quality open-source models, such as LLaMA and Mistral, has further accelerated this shift, allowing companies to bypass the costly training phase and instead fine-tune pre-trained models for specific tasks. As organizations move from experimentation to deployment, demand is growing for faster, cheaper, and more customizable AI solutions. In response, a new generation of inference platforms has emerged—designed to balance speed, cost, flexibility, and control across a range of deployment scenarios. Below, we break down the main platform types and offer a comparative cost analysis.

Three Categories of Services
1. Proprietary APIs from Hyperscalers & Foundation Model Creators
The first category encompasses the titans of the AI world, known as hyperscalers and foundation model creators. This group includes industry leaders such as OpenAI, the force behind ChatGPT; Anthropic, developers of Claude; Google DeepMind, creators of Gemini; Meta, with its LLaMA models often accessible via APIs; and Mistral, an emerging player increasingly aligning with this tier. These organizations are distinguished by their dual role: they both develop state-of-the-art AI models and provide the infrastructure to serve them. Their offerings typically revolve around public APIs—such as the OpenAI API, Claude API, or Gemini API—which allow developers to perform inference on these models. These APIs are hosted within tightly integrated cloud ecosystems, leveraging platforms like Microsoft Azure for OpenAI or Google Cloud for Gemini, ensuring high scalability and performance.
Developers and businesses gravitate toward these platforms for compelling reasons. The primary draw is access to the most advanced, frontier models available, such as GPT-4 or Claude 3, often accompanied by early releases of cutting-edge innovations. This group invests heavily in developer experience, delivering seamless software development kits (SDKs), comprehensive documentation, and robust tooling that streamline integration into applications.
However, these benefits come with notable trade offs. The cost is typically higher, reflecting not only the computational resources but also the intellectual property embedded in their proprietary models. Users have limited control over the underlying technology—model weights remain opaque, and fine-tuning is constrained to what the API permits, often requiring additional fees or specific enterprise agreements. This lack of transparency and flexibility can lead to vendor lock-in, particularly as ecosystems like OpenAI’s integration with Azure or Google’s with its cloud services create sticky dependencies.
2. Managed Inference API Platforms
The second category, inference API platforms, includes companies like Together.ai, Fireworks.ai, Replicate, Baseten, Anyscale, and Modal. These platforms carve out a niche by specializing in serving open-source or custom models—think Mistral, Mixtral, LLaMA, or Gemma—through developer-friendly APIs. They don’t typically create their own foundation models but focus instead on hosting and optimizing inference for models sourced from the broader AI community or provided by users. Their technical offerings emphasize cost-efficiency and performance, employing advanced techniques such as speculative decoding, quantization, and batched serving to reduce latency and resource consumption. Some platforms, like Together.ai, allow users to bring their own fine-tuned models, adding a layer of customization.
The appeal of these platforms lies in their balance of affordability, efficiency and control. They often deliver lower costs per token compared to proprietary models, especially when leveraging open-source models that don’t carry the same IP overhead. Users enjoy greater flexibility, with the ability to select specific models, adjust inference parameters, and, in some cases, fine-tune models to suit niche applications—options rarely available with proprietary APIs. This openness also helps developers avoid the vendor lock-in prevalent among hyperscalers, as inference API platforms tend to be more infrastructure-agnostic, integrating with a variety of cloud providers or on-premises setups.
Competition within this category is fierce. Together.ai and Fireworks.ai, for instance, prioritize rapid inference speeds, high uptime, and a broad catalog of supported models, catering to developers who value performance and variety. Others, like Replicate, focus on ease of use, while platforms such as Anyscale offer scalability for enterprise workloads. Technically, these providers often operate on thin margins for compute resources, generating revenue through value-added services like orchestration, monitoring, or multi-GPU parallelism. This makes them an attractive middle ground for those seeking efficiency and customization without the full burden of managing infrastructure.
3. DIY GPU Hosts / Infrastructure
The third category, commodity GPU hosts and developer infrastructure providers, includes players like RunPod, Modal, Lambda Labs, Vast.ai, and Banana.dev. These platforms cater to developers who crave maximum control over their AI deployments, offering raw or semi-managed GPU access rather than fully abstracted APIs. Their offerings typically include access to GPU instances—often accompanied by prebuilt containers or lightweight SDKs—allowing users to deploy their own models using frameworks like PyTorch or TensorFlow. This hands-on approach contrasts with the higher-level abstractions of inference API platforms, positioning these providers as a go-to for custom or experimental workloads.
These platforms are often the most economical option, particularly for long-running tasks or when deploying custom models that don’t require the overhead of managed services. They shine in scenarios like fine-tuning, where developers need to iterate on model weights, or edge deployments, where tailored optimization is key. For instance, Modal’s serverless architecture paired with GPU resources enables developers to scale functions dynamically, while RunPod’s bare-metal GPU rentals appeal to those running intensive, bespoke workloads. This category empowers users to dictate every aspect of their deployment, from model selection to runtime environment.
Yet, unlike the polished experiences of hyperscalers or inference API platforms, these providers demand more technical expertise. Users must handle orchestration, ensure uptime, and manage scaling—tasks that can strain small teams or tight deadlines. Support is typically leaner, and the platforms lack the refined tooling of their counterparts. Additionally, performance can vary, as some providers resell GPU capacity from underlying vendors like CoreWeave, introducing potential bottlenecks. For developers comfortable with these challenges, the low cost and unparalleled control make this category a powerful choice for tailored AI solutions.
Common Cost Elements Across the Inference Stack
Understanding the cost and pricing of AI inference platforms is key to choosing the right solution for deploying machine learning models. Each type of player comes with unique cost structures and pricing models tailored to different needs. Before diving into the specifics of each type, it’s worth noting the common cost elements that shape the inference landscape, as these underpin the financial considerations across all platforms.
Regardless of the provider, several core components contribute to the cost of running AI inference:
GPU Compute: The biggest expense, driven by the need for powerful hardware like NVIDIA’s H100 and A100 GPUs, which excel at the parallel processing required for deep learning.
Memory and Bandwidth: Essential for fast token streaming and managing large context windows, high-speed memory and sufficient bandwidth ensure smooth performance in real-time applications.
Model Licensing: A factor for proprietary models, where fees apply, though this varies depending on whether the platform owns the model or hosts open-source alternatives.
Storage: Covers the expense of storing model checkpoints, logs, user embeddings, and caching systems that boost efficiency.
Serving Infrastructure: Encompasses load balancing, autoscaling, and failover mechanisms to keep services reliable under varying workloads.
Developer Tools: Includes the development and maintenance of APIs, SDKs, monitoring, tracing, and logging features that streamline the user experience.
Support and R&D: Reflects ongoing investments in engineering, optimization, and innovation to keep the platform competitive.
These elements form the foundation of inference costs, but their weight and how they’re managed differ significantly across the three types of players. Let’s explore each in detail.
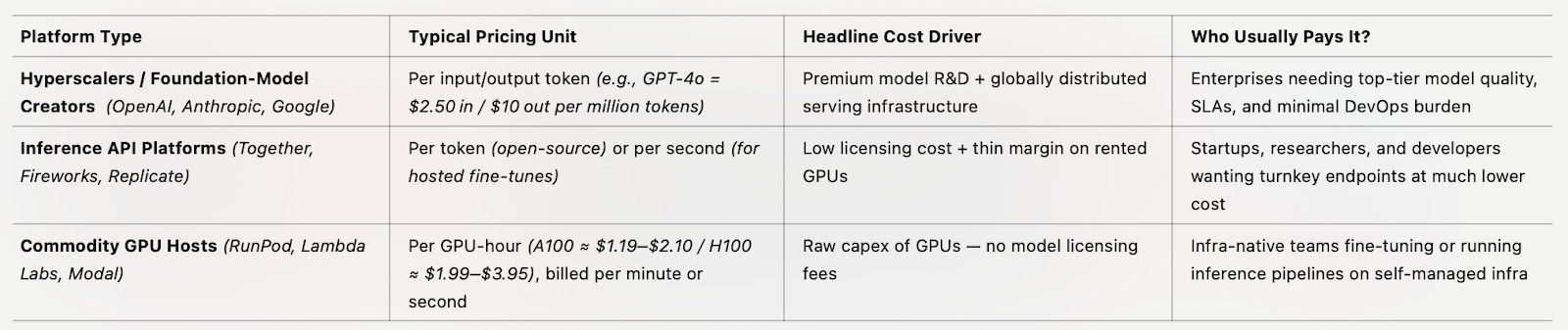
Price Comparison
1. Proprietary APIs from Hyperscalers & Foundation Model Creators
Companies like OpenAI, Anthropic, and Google DeepMind sit at the premium end of the spectrum, offering top-tier, proprietary models integrated with robust cloud ecosystems. Their cost is notably high due to the resources required to maintain their cutting-edge offerings. They rely on premium infrastructure powered by the latest GPUs. Since they develop their own models, there are no external licensing fees, but the internal research and development costs are substantial and baked into their pricing. Their serving infrastructure is another major expense, with globally distributed systems ensuring high availability and low latency, while extensive developer tools—like polished APIs and comprehensive support—add to the overhead.
Pricing reflects their premium positioning. OpenAI’s GPT-4.5, codenamed Orion, is priced at $75 per million input tokens and $150 per million output tokens, making it one of the company’s most expensive offerings to date. Designed for advanced tasks that demand high accuracy and reasoning depth, it caters primarily to enterprise-grade applications. Anthropic’s Claude 3.7 Sonnet, known for its hybrid reasoning capabilities, is more cost-effective—priced at $3 per million input tokens and $15 per million output tokens—but still clearly targets the high end of the market. Despite the enormous infrastructure demands, both companies reportedly maintain API gross margins around 55%, buoyed by strategic partnerships—Microsoft, for example, offsets some of OpenAI’s costs in exchange for infrastructure exclusivity and revenue sharing.

Customers pay a premium for unparalleled model quality, stability, and brand trust, making these hyperscalers the default choice for enterprises that value speed, reliability, and simplicity. But for startups and smaller teams, relying on these APIs at scale can be financially unsustainable—API costs can quickly balloon, making inference economically infeasible without aggressive optimization or alternative solutions. This is where a second group of providers—inference API platforms—emerge to offer more control, flexibility, and cost efficiency.
2. Managed Inference API Platforms
Inference API platforms such as Together.ai, Fireworks.ai, and Replicate offer highly competitive, usage-based pricing models for serving open-source and custom AI models, providing a cost-effective alternative to proprietary providers. These platforms combine flexible pricing—whether per-token or per-second—with generous discounts, making them ideal for developers, startups, and researchers seeking performance without premium costs. Below is a detailed breakdown of their pricing structures and discount offerings.
The AI inference platform industry has embraced usage-based pricing models that align costs with computational demands, ensuring accessibility and scalability for diverse users. Together.ai employs a per-1,000-tokens pricing structure based on model size, with rates starting at $0.0001 for models up to 3 billion parameters and reaching $0.003 for larger models between 40.1 billion and 70 billion parameters, supplemented by hosting fees like $0.52 per hour for fine-tuned models up to 7 billion parameters and enhanced by $25 in free credits for new users and discounts up to 60%. Fireworks.ai uses a per-million-tokens model, with costs ranging from $0.10 for small models under 4 billion parameters to $3.00 for complex mixture-of-experts models like Mixtral, offering frequent discounts from 10% to 50% and special rates for students and NGOs. Replicate distinguishes itself by billing per second of compute time, starting at $0.0001 per second for public CPU usage and scaling to $0.0058 per second for high-end GPU configurations like 8x Nvidia A40, with discounts up to 65% and additional reductions for educational and non-profit users. These platforms collectively prioritize flexible, scalable pricing, bolstered by promotional offers and tiered discounts, making AI inference cost-effective for individual developers, startups, and large organizations alike, as confirmed by recent pricing data and coupon aggregators.

3. DIY GPU Hosts / Infrastructure
Commodity GPU Hosts like RunPod, Modal, and Lambda Labs cater to developers seeking maximum control and the lowest possible compute costs—though this comes with a labor-intensive trade-off. These platforms operate on a bare-metal model, charging users directly for GPU time. As of 2025, prices range from $1.19 to $2.99 per hour for A100s, and $1.99 to $3.95 per hour for H100s, with even lower rates available for older GPUs (like the A40, A10G, or T4), spot instances, or community/shared deployments.
Unlike inference API platforms, there are no licensing fees, as users bring their own models—typically open-source—and handle the full deployment stack. Infrastructure beyond GPU provisioning is minimal: load balancing, autoscaling, model serving, and failover are all up to the user. Modal, however, offers per-second billing, which is useful for short or bursty jobs.
Most platforms apply a 10%–30% markup on base compute costs, keeping prices transparent and competitive. This approach delivers the lowest per-unit compute cost, especially for fine-tuning, custom pipelines, or long-running inference. It’s a favorite for researchers, ML engineers, and cost-sensitive startups who prioritize flexibility over convenience.
That’s it for now. Next, we’ll dive into deployment-stage price comparisons and how teams choose between AI API services.