
The End of Big, Dumb AI Data
AI Data Operations Enter the Smart Phase: Why Quality & Strategy Now Beat Quantity

Over the holidays, we’ve been busy polishing our business intelligence platform—mainly by experimenting with language models and vector-based search to give our accreditation-as-a-service lead gen tool a boost. Meanwhile, the buzz about DeepSeek and plenty of responses from major AI and AI infrastructure companies has only underscored the impact and need for rock-solid data management and high-quality datasets.
Sure, that might not sound earth-shattering if you’ve been around data for a while. But it’s amazing how fast the conversation has circled back to this point. We’re hitting a ceiling with huge, generic datasets scraped from the web, and if we’re serious about leveling-up AI—especially for business-critical use cases—specialized, high-quality data . That switch is set to change how companies plan their budgets, design their data strategies, and ultimately who wins or loses in the market. Some will burn piles of cash on AI ventures that go nowhere, while others will treat data like a moat and shoot ahead.
For years, the go-to move in artificial intelligence was simple: build bigger models and feed them more data. And for a while, it paid off, language models blew us away with what billions (or trillions) of tokens could accomplish. But we’ve reached the so-called “data wall,” where truly one-of-a-kind text is scarce and brute-force scaling has diminishing returns. Ironically, many of today’s top-tier AI models can still do wonders with less data—provided it’s the right data, curated with real care. Spoiler: it’s no longer about making everything bigger—it’s about focusing on better data to help these models excel.

Smaller models benefit more from incremental fine-tuning, while larger models require far fewer fine-tuning tasks to reach near-optimal performance.Source: Scaling Instruction-Finetuned Language Models, Chung et al. (2022) arXiv:2210.11416
From Quantity to Quality … and Beyond
These days, it’s hard to escape talk about AI without the heavy bajilion price tag attached to everything. But behind the scenes, many of us in the industry are coming to the same conclusion: simply throwing more data at bigger models has probably run its course. Once a model has soaked up the entire internet, the gains you get from piling on more of that same content tend to shrink fast.
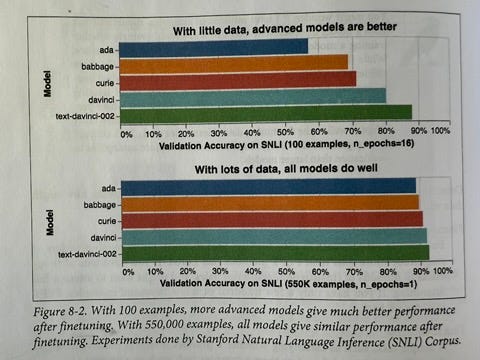
My other takeaway from this graph is that as the model becomes more advanced, incrementing improvement with more data is actually not that significant, inverse scaling law in AI data. Source: AI Engineering, Chip Huyen, 2024
What DeepSeek (Probably Smartly) Did with Their Data
If you’ve been following AI trends, you’ve heard that the old “collect all the data on Earth and hope for the best” playbook is on its last legs. DeepSeek (or “DeepSeq,” depending on who you ask) seems to be betting big on quality over quantity—and from what we can glean, it’s paying off. So how do they actually do it?
1. Long Reasoning Traces: Teaching the Model to “Keep the Thread Forever”
DeepSeek is known for churning out really long synthetic conversations or reasoning paths—tens of thousands of tokens, all in one coherent thread. Instead of the usual “short Q&A plus a thumbs-up or thumbs-down from a crowdworker,” they let an initial “alpha” model unroll its thoughts in detail. Then human annotators come in to fix any weird tangents or factual slip-ups, effectively polishing these meandering dialogues into top-quality training data. Imagine giving the AI a chance to explain itself step by step, like a teacher breaking down a math proof, rather than just stating the final answer. That extra granularity teaches the AI to maintain context across way longer sequences.
2. From RLHF to DPO: When Traditional Feedback Isn’t Enough
Most large models rely on RLHF—Reinforcement Learning from Human Feedback—to refine their outputs. But that approach is typically built around short snippets. DeepSeek, however, uses DPO (Direct Preference Optimization), which is a more flexible way of integrating human (and even AI-verified) feedback into these colossal, multi-turn dialogues. Because they’re dealing with lengthy, synthetic data, a standard RLHF pipeline would break down—so DPO is their “secret sauce.” It streamlines how they label preferences on these extended “reasoning threads,” and it opens the door to advanced techniques like “Reinforcement Learning from AI Feedback” (RLAIF). In plain English: DeepSeek can incorporate AI-driven correctness checks on top of human insights, making it easier to generate (and verify) truly valuable data.
3. Distillation: Less Model, More Brainpower
Then of course we need to mention distiliation. If you’re training a massive alpha model on these long, curated data traces, you might worry about cost and deployment headaches. That’s where distillation swoops in. With distillation, you train a smaller “student” model to capture most of what the bigger “teacher” model learned—basically 80-90% of the smarts at a fraction of the size. DeepSeek’s approach likely looks like this:
1. Let the alpha model generate tons of sophisticated reasoning sequences.
2. Clean and refine them via DPO and human checks.
3. Train a leaner model on that curated data, so you get something cheaper and faster to run.
4. Rinse and repeat, iterating until you have a model that’s both powerful and efficient.
DeepSeek likely avoids the “data sprawl” problem that has plagued many AI projects. Instead of collecting every obscure meme or mislabeled forum post, they focus on data that explicitly boosts the model’s reasoning ability. That’s good news for organizations worried about skyrocketing training costs and infinite compute budgets.
After the Data Wall: Data Coverage and Quality
By now, most agree scraping every random webpage on Earth has given us a decent baseline for large language models. If we want advanced AI that can juggle multiple tools, reason like a skilled domain expert, or operate as a truly efficient business solution, we need far more specialized data. And in many cases, we’ll have to build (or synthesize) that data ourselves.

For Llama 3, different training phases have different optimal domain mixes. Source: AI Engineering, Chip Huyen, 2024
1. Coverage
• What it means: Does your dataset span the domains and tasks your model actually needs to master—including the right balance of text, code, and math examples?
• Why it matters: While most training sets are still dominated by natural language text, there’s a common belief in AI circles that high-quality code and math data (even if it’s only a small fraction of the total) can supercharge a model’s reasoning abilities. For instance, if code + math together make up only ~12–13% of your dataset, that portion might nonetheless yield outsized gains in problem-solving benchmarks. Simply put, if your AI must handle advanced calculations or code-based tasks, don’t rely solely on everyday language corpora—ensure you have enough specialized data to teach those skills effectively.
2. Quality
• What it means: Even if your dataset hits all the right categories (text, code, math), is it accurate and well-structured?
• Why it matters: Perfect coverage without careful vetting can backfire. Feeding your model buggy code or incorrect proofs sows confusion and bad habits. A robust dataset isn’t just about variety, but about correctness, consistency, and coherence.
The Characteristics of High-Quality AI Data
Different frameworks label them differently, but according to Chip Huyen in her excellent book AI Engineering, they often include:
1. Completeness : Do you have all the steps or fields you need? For code, that’s the full function and dependencies; for math, every sub-step in a derivation.
2. Accuracy: Are code snippets truly functional, and are math solutions logically sound? One flawed example can mislead the model’s reasoning.
3. Consistency: Does your formatting or style remain uniform? Letting code style or math notation vary wildly can hamper learning.
4. Timeliness: Do your samples reflect current frameworks, library versions, or up-to-date math conventions? Out-of-date references may limit real-world performance.
5. Validity: Do data points follow the rules or schemas you set? Code should compile or run; math steps should be verifiable.
6. Uniqueness: Avoid repeated items that add no real novelty. This is crucial for code/math, where the same solution might appear in only slightly tweaked forms.
Frontier AI Use Cases That Haven’t Arrived (Yet)
So, what exactly are these “frontier” tasks that can’t rely on random web text alone? In short, they’re the kinds of advanced enterprise scenarios that demand multi-step reasoning, specialized domain expertise, or intricate workflows—and they’re not fully here yet, largely because the data to train them doesn’t exist in a convenient, ready-to-ingest form.
Think about an AI coordinating multiple factory robots, or a financial model analyzing complex data streams from half a dozen internal tools—these aren’t your typical web-scraped use cases. Most big companies haven’t publicly released the logs, error states, or advanced instructions needed to teach an AI how to operate in these specialized environments. As a result, the biggest bottleneck isn’t the algorithm; it’s the lack of relevant training data.
That’s why many in the AI field see frontier data as the next major unlock: If you can systematically create or gather the step-by-step logs, domain-specific examples, and realistic “edge cases” that reflect actual enterprise workflows, you can finally train a model to handle them. Forget scraping more blogs or social media rants—these advanced tasks require purpose-built datasets that show the AI exactly how to navigate complex, real-world processes. And until those datasets exist, the most impressive (and potentially transformative) uses of AI will remain stuck in the realm of possibility rather than day-to-day production.
1. Multi-Tool Agents
• Example: An AI that queries an internal database, runs a Python script, then posts the final result to Slack.
• Data Needed: You’ll likely have to record or simulate real interactions—complete with error states when the script bombs out or when Slack’s API fails. This ensures the model learns genuine multi-step sequences, not just single-turn Q&A.
2. Industrial or Scientific Workflows
• Example: A robotics assembly line that uses sensor data (like temperature or torque) to decide the next step.
• Data Needed: High-fidelity sensor logs with domain-specific annotations—plus synthetic edge cases for those “once in a blue moon” temperature spikes or mechanical lags. If you never train the model on them, it’ll crash in real life.
3. Code-Focused or Tech-Stack–Specific
• Example: Teaching an LLM to debug or generate code in a specialized environment (say, FPGA programming or a very niche library).
• Data Needed: Well-labeled, curated code samples, possibly spiked with synthetic variants that test corner cases or library updates the model wouldn’t see otherwise.
4. Expert-Level Reasoning
• Example: A legal AI that can interpret contract clauses step by step, citing relevant case law along the way.
• Data Needed: Expertly verified texts from real attorneys, plus synthetic expansions to handle out-of-left-field hypotheticals. Because let’s face it: real-world legal docs can get weird, and your model should be ready for that.
New Flavors of AI Data
As artificial intelligence leaps past basic classification and single-turn Q&A, new data flavors have emerged to tackle everything from multi-step logic to complex tool usage. In the following sections, we’ll explore these fresh approaches—like reasoning-heavy “chain-of-thought” sets, agentic tool-interaction logs, and multimodal or simulation-based data—and show how they’re structured, why they matter for next-gen AI, and what makes them distinct from the simple “input → label” datasets of the past. By understanding these advanced data types and seeing concrete examples, you’ll gain a clearer picture of how AI can handle deeper, more diverse real-world challenges.
1. Old: Traditional ML Classification
A classic supervised learning setup where each example has a single label—for instance, determining whether a product review is positive or negative, or predicting if a transaction is “fraud” or “not fraud.” It’s usually just one input (e.g., a text snippet) and one label.
• Forms the backbone of early machine learning use cases (sentiment analysis, spam detection, etc.).
• Great for straightforward tasks with well-defined labels, but lacks the complexity needed for advanced reasoning or multi-step logic.
{
"id": "ml_class_01",
"text_input": "This product was exactly what I needed, highly recommend!",
"label": "positive"
}2. Old: Basic Q&A (Prompt → Answer) Datasets
A short prompt (a question) paired with a single best answer. Think about a dataset that simply asks, “Who is the CEO of Company X?” and expects one concise response.
• Easy to create and crowdsource.
• Commonly used for single-turn language-model training (e.g., SQuAD or simple RLHF tasks).
• Doesn’t teach the model how it got the answer; just Q → A.
{
"id": "qa_014",
"prompt": "Who is the current CEO of Company ABC?",
"best_answer": "John Doe"
}3. Reasoning-Heavy / Chain-of-Thought Datasets
Each record shows multiple steps of the model’s or human’s thought process, rather than a single final answer. For instance, math derivations, legal argument logic, or multi-hop question answering.
• The model sees how a conclusion is reached.
• Critical for tasks needing multi-turn or multi-step reasoning (e.g., advanced math, legal interpretation).
• Generating or verifying these sequences can be labor-intensive—especially if you want them error-free.
{
"id": "reason_220",
"question": "Calculate the integral of 2x + 3 from x=0 to x=4.",
"chain_of_thought": [
"1) Integral of 2x is x^2, integral of 3 is 3x.",
"2) Evaluate x^2 + 3x at x=4 and x=0.",
"3) At x=4, total is 16 + 12 = 28; at x=0, it's 0.",
"4) 28 - 0 = 28."
],
"final_answer": "28"
}4. Composite (Multi-Domain) Datasets
A curated blend of different data sources—legal text, e-commerce logs, medical records, code snippets, etc. Each entry typically notes which domain it belongs to.
• Helps the model learn to switch contexts on the fly (e.g., from a shipping query to a legal clause).
• Reflects real-world enterprise scenarios where data spans multiple departments or specialties.
• Must keep metadata consistent (e.g., domain tags, timestamps) to avoid confusion.
{
"id": "composite_005",
"domain": "legal",
"text": "Under Section 4.1, the buyer has 30 days to request a refund.",
"metadata": {
"source": "contract_doc_legalteam",
"date": "2025-04-10"
}5. Agentic / Tool-Interaction Data
Logs that capture the AI’s multi-step interactions with different tools or APIs. For example, an AI might query a database, analyze the results in Python, then post a summary somewhere else.
• Teaches the model how to take actions beyond simple Q&A—like calling external services or handling errors.
• Key to building “agents” that can chain tasks across multiple platforms or tools.
• Data can be messy since each tool has unique inputs/outputs.
{
"session_id": "agent_8392",
"steps": [
{
"step_number": 1,
"tool_name": "InventoryDB",
"tool_input": {"query": "SELECT stock FROM products WHERE id=45;"},
"tool_output": {"stock": 12},
"reasoning": "Got stock count. Next, check reorder threshold."
},
{
"step_number": 2,
"tool_name": "ReorderScript",
"tool_input": {"current_stock": 12, "threshold": 10},
"tool_output": {"action": "No reorder needed"},
"reasoning": "Stock is sufficient; script says no reorder."
}
]
}6. Multimodal Datasets
Each entry ties text to another modality (images, audio, video, or sensor data). For instance, a product description plus an image link.
• Many real-world tasks involve visual or audio cues.
• Models can learn to interpret multiple data streams simultaneously (e.g., describing an image or summarizing a video).
{
"id": "multi_031",
"text_description": "Red running shoes, size 9",
"image_path": "images/run_shoe_red.jpg",
"label": "footwear"
}7. Simulation / Synthetic Environment Data
Generated from a virtual environment or simulator (like a robotics training sim). The dataset includes details about the environment state, the agent’s actions, and the outcomes.
• Perfect for training AI on rare edge cases that are hard to capture in the real world.
• Common in robotics, self-driving cars, or industrial automation—where physical testing can be risky or expensive.
{
"scenario_id": "sim_101",
"environment": "warehouse_sim",
"robot_position": { "x": 4.2, "y": 7.9, "theta": 90 },
"action_taken": "pick_box",
"result": "success",
"notes": "Simulated pallet approach with overhead clearance of 5 inches."
}8. Hyper-Specialized Domain Logs
Detailed records from niche fields—like aerospace engine logs, advanced medical device readouts, or specialized financial-trading transcripts.
• If your AI must excel in a domain where public data is non-existent or incomplete, you rely on these real-world logs from enterprise systems.
• Often protected by security or privacy constraints, making data collection tricky.
{
"record_id": "hyper_774",
"domain": "biotech_lab",
"sensor_data": {
"temp_c": 37.2,
"ph_level": 6.9,
"oxygen_ppm": 4.1
},
"timestamp": "2025-06-12T10:05:00Z",
"event_summary": "Cell culture showing accelerated growth phase."
}The Role of Synthetic Data: Bridging Gaps—But at a Cost
We’ve practically tapped out all the public web text we can find, so it’s no surprise AI-generated (i.e., synthetic) data is emerging as the next big thing. Instead of scraping more cat memes or half-redundant news articles, you can produce the exact examples your model needs—whether that’s multi-step tool usage, specialized compliance logs, or chain-of-thought expansions for advanced math. Sound like a cure-all? It can be, but there are real trade-offs.
Why Synthetic Data Matters
1. Filling Coverage Gaps
Don’t have a huge dataset of “employee scheduling across multiple time zones”? Just synthesize it. That means you can quickly spin up data for tasks that simply don’t exist in the wild—like chaining Slack, Jira, and Python.
2. Privacy & Sensitivity
Enterprises dealing with confidential or personal data (think finance or healthcare) may not want to expose real logs, so they generate anonymized or lightly-altered synthetic sets. This protects user data while still giving the model training examples relevant to real-world workflows.
3. Rapid Experimentation
If you suspect your AI might benefit from 10,000 more “refund scenario” examples, it’s easier (and cheaper) to produce them artificially than to wait months for your real customers. That’s huge for iterative development—just keep a close eye on quality (we’ll get there in a moment).
The Dangers of Synthetic Data
1. “Garbage In, Garbage Out” Amplified
Synthetic data can be downright wrong if your base generation model or script has errors. The AI then trains on flawed examples, reinforcing shaky logic or misinformation. Instead of solving your coverage gap, you’ve just created 10,000 unhelpful samples.
2. Superficial Imitation
If the synthetic process merely copies patterns without real understanding, your AI might learn to “fake” reasoning. It’ll parrot the style of multi-step logic but can’t adapt in truly novel scenarios.
3. Feedback Loop Risk
Generating data with an AI to train another AI can lead to a self-referential loop. Over time, small inaccuracies compound, and your model’s outputs drift away from genuine real-world fidelity. Researchers sometimes call this “model collapse.”
Effective Data Management: What Enterprises Should Do (But Probably Won’t)
DeepSeek’s strategic approach is a glimpse into the future—but most enterprises are far from reaching this level of efficiency. AI management in large companies will remain bloated, reactive, and wasteful. When something becomes a corporate shiny object, like enterprise AI, it inevitably attracts more process, politics, and bureaucracy.
Most organizations are nowhere close to implementing strategic AI data management—and realistically, they won’t be anytime soon. Instead, they’ll throw money at the problem, just as they always have. In traditional enterprise settings, data management isn’t seen as a competitive advantage; it’s treated as an IT function, a cost center to be maintained rather than optimized. And as AI adoption accelerates, it’s poised to inherit these same inefficiencies. For those who actually want to break the cycle, here’s what should be done, I think:
1. Pinpoint High-Impact Data Domains
Instead of hoarding every possible dataset, enterprises should identify the highest-value data for their AI use cases. If AI is being used for legal interpretation, investing in high-quality, expert-labeled legal contracts is more valuable than scraping public court filings without context. But in reality, most enterprises will continue treating all data as equally important, leading to bloated, unfocused datasets.
2. Balance Real vs. Synthetic Data
Synthetic data can bridge gaps, but real-world data is still the strongest foundation. The ideal mix (e.g., 70% real, 30% synthetic) depends on the use case, but the key is tracking performance and adjusting. The problem? Enterprises prefer volume over precision. Many will flood their models with synthetic data without proper validation, leading to models that sound convincing but lack real-world accuracy.
3. Validate, Validate, Validate
The worst mistake enterprises make is treating data validation as a secondary step. AI should not be trained on unchecked, low-quality, or inconsistent data, yet that’s exactly what happens in large-scale corporate data lakes. Companies should build automated QA pipelines and enforce human oversight—but most won’t. They’ll rely on AI to validate its own synthetic data, creating feedback loops that degrade performance over time.
4. Plan for Versions and Iterations
AI data should be versioned like software, allowing for rollbacks, experiments, and structured updates. Instead, most enterprises still operate with rigid, static data systems that make real iteration difficult. Without agile data management, AI teams will continue training on outdated, untracked, or poorly labeled data, wasting both time and compute resources.
5. Leverage Expert Labelers Where It Matters
For specialized AI use cases—law, medicine, finance—real domain expertise is essential. Enterprises should invest in human experts to refine datasets, especially where errors can have legal or financial consequences. Instead, most companies will choose the cheapest possible data annotation solutions, leading to AI models that confidently produce incorrect results.
Where This Is Actually Headed
In the best-case scenario, a handful of companies will treat AI data management as a strategic function, gaining a competitive moat through proprietary, high-quality datasets. In the more likely scenario, most enterprises will continue throwing money at the problem, resulting in data bloat, inefficiencies, and diminishing returns on AI investments.
The Future of Data Labeling: Surviving the AI Shift
It seems like a new data labeling company is born and dies every week. The market is saturated, and companies like Scale AI, Invisible Technologies, and Appen must evolve or risk obsolescence.

How many data labelling shops do we need?
1. The Shift Toward New Data Need
Basic labeling is becoming commoditized. Future demand will focus on specialized, domain-specific data (legal, medical, industrial AI) rather than mass annotation at scale.
2. A Marketplace With Few Differentiators & Scaling Challenges
The data labeling industry has the same brutal economics as Uber/Lyft: minimal differentiation, cutthroat pricing, and the constant race to optimize unit economics. Companies like Scale AI are trying to escape the commodification trap by pivoting into full-stack AI data management. Others won’t be so lucky.
3. Revenue and Industry Pivot
Many firms pivot across industries—most famously Scale AI, which has moved from self-driving cars to e-commerce to defense. Scale’s annual revenue from its latest pivot into federal defense likely sits around $80–100M this year (vs. its projected $1.4B total ARR for 2024). Survival depends on shifting from pure labeling to full-stack AI data management. And that’s why we’re seeing all these podcasts.


Scale AI’s publicly detectable direct federal revenue and its largest agency customers. Source: Procure.FYI
Bringing It All Together
AI model performance will continue to improve, and overall data demand will grow, but the amount of data needed for each incremental enhancement will become more optimized, reducing data intensity per unit of progress. I’m seeing signs of a potential plateau in the AI CapEx boom here and there—but are we there yet? We’ll see in two years.
In AI, we started like the early industrialists—assuming more data was the answer to everything. But just as the energy sector learned to do more with less, AI is entering a phase where efficiency matters more than sheer scale. The future won’t be won by those who hoard data, but by those who know exactly which data to use and when.

Interesting point