


AMD’s Two-Year Shot
ROCm: CUDA, Woulda, Shoulda

We’re at an interesting inflection point in the chip industry, and I’ve been thinking about the ecosystem dynamics amid all the moving pieces. Several factors have captured my attention and suggest the competitive landscape is shifting.
First, we’re moving toward a more inference-centric world. I discussed this shift over the last month, on changes in both data usage and capital expenditures. The Financial Times recently echoed this sentiment, highlighting Barclays’ research predicting that while NVIDIA will retain near-total dominance in AI training chips, it may only capture about 50% of the inference market.
Larry Ellison recently highlighted Oracle’s substantial purchase of 30,000 AMD GPUs, marking a notable pivot away from NVIDIA dependency.
Ellison previously remarked that CEOs must practically “beg” NVIDIA’s Jensen Huang over dinners at Nobu Palo Alto to secure GPU allocations. Rumors and whispers, I heard, allegedly, that many chief executives in the ecosystem are growing tired of what feels like an obligatory tribute at Jensen’s global tour stops just to secure their GPU supplies.
Beyond sentiment, there’s also a clear strategic rationale for companies diversifying away from NVIDIA to avoid vendor lock-in. With TSMC’s CoWoS packaging bottleneck expected to last another two to three years, NVIDIA’s GPU availability remains constrained.
Then there’s Intel’s recent CEO transition to Lip-Bu Tan, Microsoft scaling back some data center expansions, and CoreWeave’s upcoming IPO next week.
It’s a very interesting time, and I just wanted to jot down some thoughts on what I think is happening.
1. Where AMD’s Opportunity Lies
I think AMD has a critical two-year opportunity in AI compute, data center acceleration, and high-performance computing is emerging from several market forces reshaping the GPU landscape. AMD has an opportunity to capitalize on this, particularly with MI300 and improvements in its ROCm software stack, if its strategy is well executed.
NVIDIA’s Supply Constraints and Market Saturation
NVIDIA’s AI GPUs, such as the H100, are in high demand, leading to persistent shortages. The GPU shortage is particularly acute for AI training, with impact on innovation and growth. This creates an opening for AMD, as enterprises and cloud providers seek alternatives. AMD can leverage its Instinct MI300 series to meet demand, especially for customers unable to secure NVIDIA GPUs. Online comparisons have shown AMD’s MI300X offering high compute power, nearly doubling throughput compared to NVIDIA’s H100 in some benchmarks. While NVIDIA’s supply issues are short-term, the two-year window allows AMD to establish itself before improvements in NVIDIA’s supply chain potentially close this gap. By early 2027, AMD could become more competitive as it addresses software and scaling challenges.
Enterprise AI and the Shift to Multi-Vendor Strategies
Major cloud providers and enterprises are actively diversifying their AI compute stacks to avoid vendor lock-in. This diversification is driven by the need for risk management and ensuring continuity, especially in critical AI workloads. We are seeing increased adoption of multi-vendor strategies. However, AMD must ensure compatibility and performance to compete with NVIDIA’s established ecosystem.
AI Inference, Cost Pressures, and AMD’s Role
The future of AI workloads involves far more inference than training, driven by the deployment of AI models at scale. Online reports indicate that inference workloads are memory-intensive, and AMD’s GPUs, with larger on-chip memory (e.g., 192 GB on MI300X vs. 80-94 GB on H100), are competitive. AMD’s tunability and lower costs make it a viable alternative, especially for customized data center needs.
The AI compute market is also under significant cost pressure, with enterprises seeking alternatives to NVIDIA's high-priced GPUs like the H100, reported at up to $40,000 per unit NVIDIA H100 Pricing. AMD has positioned itself as a cost-effective competitor, with the MI300X priced between $10,000 and $15,000, appealing to startups, research institutions, and enterprises for inference and mid-scale training AMD MI300X. Benchmarks show MI300X can run large language models like Llama3-70B-Instruct on a single chip, potentially reducing infrastructure costs compared to H100, which may require multiple GPUs AMD LLM Benchmarks.
NVIDIA's Blackwell series, announced in March 2024, includes B100 and B200, targeting data center AI workloads, while AMD's roadmap includes MI325X (Q4 2024) and MI355X (H2 2025), aiming to challenge that. The next stage after Blackwell is NVIDIA's Rubin architecture, expected in early 2026, competing with AMD's CDNA4.
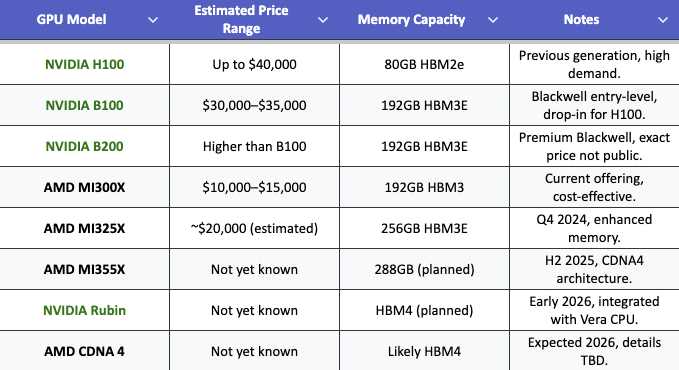
While NVIDIA's GPUs excel in raw computational power, especially in FP8 formats, AMD's higher memory capacity (e.g., MI325X's 256GB vs. Blackwell's 192GB) offers an advantage for memory-intensive AI tasks. This memory edge, combined with lower pricing, enhances AMD's value proposition for cost-sensitive applications. NVIDIA Rubin’s mass production is scheduled for late 2025 and availability in 2026. This timeline could shift the competitive equation, accelerating NVIDIA's lead in performance and cost-efficiency, but manufacturing constraints at TSMC, where both companies produce chips, may limit supply, potentially benefiting AMD's market share growth.
The Open-Source AI Shift and ROCm’s Prospects
Many overlooked AMD’s greatest strength - its ability to innovate in chip architecture. AMD had engineers like Raja Koduri in GPUs and Jim Keller in CPUs. Keller, in particular, played a pivotal role in developing AMD’s 64-bit x86 architecture—technology so foundational that Intel eventually licensed it from AMD. However, hardware innovation alone is not enough. To fully capitalize on its architectural strengths, AMD must bridge the gap between cutting-edge hardware and a fully optimized software stack. This is where the industry consensus lies and where I am beginning to see notable improvements.
For years, NVIDIA has set the gold standard in GPU compute ecosystems, largely due to its early investment in CUDA, launched in 2007. By building robust developer tools, a well-defined API, and extensive support resources, NVIDIA created a deeply integrated ecosystem that became the default for high-performance GPU computing. More importantly, CUDA introduced a unified software and hardware architecture, optimizing data transfers and execution models—critical advantages in AI workloads, where software efficiency is just as important as raw compute power.
AMD, by contrast, launched ROCm (Radeon Open Compute) nearly a decade later in 2016, leaving it at a significant disadvantage. By that time, NVIDIA had already entrenched itself in academia, research labs, and enterprises by strategically distributing CUDA development kits to universities, ensuring an entire generation of engineers and researchers were trained in its ecosystem.
Early versions of ROCm struggled with complex setup requirements, sparse documentation, and limited support for AMD’s own GPU lineup. Meanwhile, PyTorch and TensorFlow—two of the most widely used AI frameworks—were built around CUDA, reinforcing NVIDIA’s dominance. Even today, despite official ROCm support in PyTorch, performance still lags behind CUDA, and the lack of Windows support remains a major limitation for developers who rely on cross-platform compatibility.
2. ROCm’s Strategy and Challenges Ahead
George Hotz: AMD’s driver bricked my computer
ROCm, AMD’s open-source platform for GPU computing, faces significant practical challenges that hinder its widespread adoption compared to NVIDIA’s CUDA. These challenges include limited cross-platform compatibility, the complexity of migrating from CUDA, insufficient community engagement, and inconsistent performance due to software limitations.
Cross-Platform Compatibility
ROCm’s primary support for Linux restricts its appeal in enterprise environments where Windows dominates. Unlike CUDA, which offers mature compatibility with both Linux and Windows, ROCm’s Windows support remains underdeveloped despite ongoing efforts by AMD. This gap limits ROCm’s ability to compete in broader markets.
Complexity of Migrating from CUDA
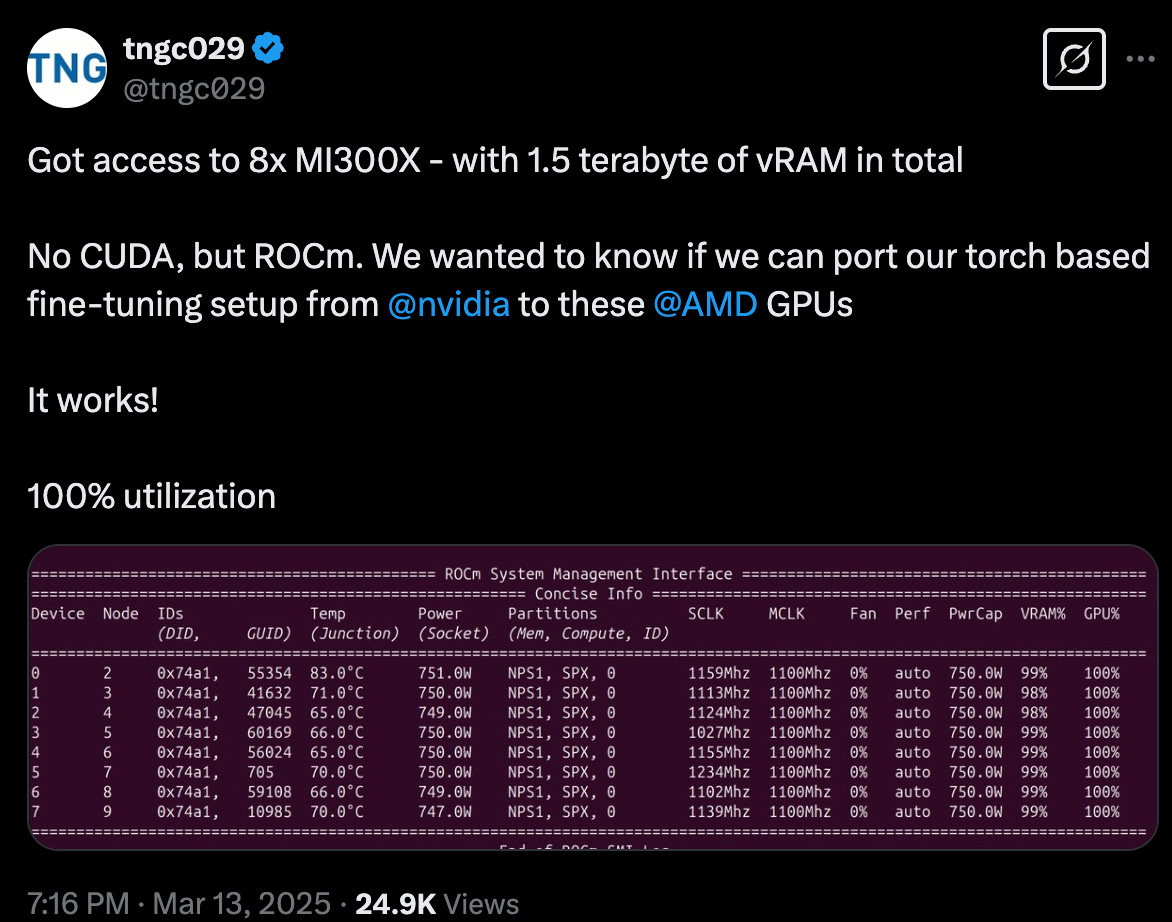
CUDA > ROCm. It can be done. Source: https://x.com/tngc029/status/1900325224895189008
Transitioning from CUDA to ROCm is a major hurdle for developers. While AMD’s HIP tool assists in porting CUDA code to AMD GPUs, the process is complex, often requiring months of debugging, tuning, and adjustments. This time-intensive migration discourages developers from switching platforms.
Open-Source Nature and Community Engagement
ROCm’s open-source framework fosters innovation but relies heavily on community participation, which currently lags behind CUDA’s robust, proprietary ecosystem. Without a larger, more active community to contribute code and support, ROCm’s growth and refinement are slowed.
Performance Inconsistency
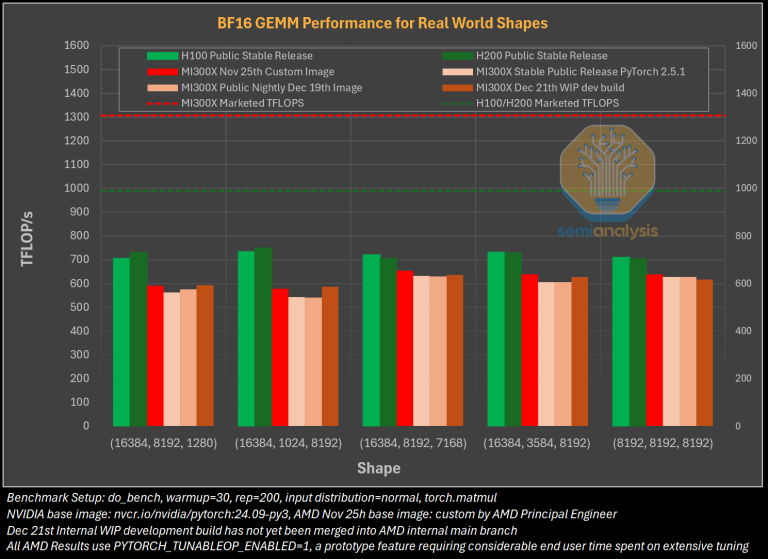
Source: SemiAnalysis
Despite hardware strengths, such as the MI300X, ROCm’s performance is inconsistent compared to NVIDIA’s H100. For instance, the MI300X is 14% slower in BF16 training and 22% slower in FP8 training due to less optimized software in ROCm, compared to CUDA’s mature optimizations like TensorRT-LLM. While it matches the H100 in some inference tasks, its training performance highlights the need for further software development.
3. How AMD Is Tackling Its Biggest Challenges
Rather than simply expanding its own ecosystem, AMD is taking a differentiated approach by prioritizing open-source software and portability. Instead of forcing developers to abandon CUDA, AMD is making it easier to port existing CUDA applications onto AMD GPUs. This strategy plays to AMD’s strengths—openness, flexibility, and community-driven development—positioning ROCm as a viable alternative to NVIDIA’s proprietary CUDA ecosystem.
Advantages of AMD’s Open-Source ROCm Platform
Broader Accessibility – Open-source platforms encourage extensive community collaboration, driving faster innovation, quicker bug fixes, and continuous improvement—areas where closed systems like CUDA often lag.
Flexibility & Customization – Unlike NVIDIA’s tightly controlled CUDA, ROCm gives developers greater low-level access to optimize performance, which can be crucial for specialized AI workloads.
Reduced Vendor Lock-In – By adopting ROCm, enterprises gain an alternative to NVIDIA, reducing dependence on a single vendor and mitigating the risk of rising GPU costs or proprietary software constraints.
AMD’s Strategy to Accelerate ROCm Adoption
Source: AMD Github
To make ROCm more competitive, AMD is investing in key areas to address its most pressing challenges:
Improving Portability with HIP – AMD is actively enhancing HIP (Heterogeneous-Compute Interface for Portability), which translates CUDA applications for AMD GPUs. The goal is to automate more of the process, reducing manual intervention and making it easier for developers to migrate existing workloads. If successful, this could significantly lower the barrier to adoption.
Expanding Windows Support – One of ROCm’s biggest limitations has been its lack of full Windows compatibility, a key factor restricting broader enterprise adoption. Acknowledging this, AMD has made Windows support a priority, with full PyTorch support expected by Q3 2025. Recent development progress is visible on ROCm’s Windows branch on GitHub, signaling AMD’s commitment. However, broader community engagement remains limited, with much of the progress currently driven by AMD’s internal engineers. That said, not all ROCm-related development files are publicly available, meaning community contributions may not be fully reflected on GitHub. For ROCm to truly compete with CUDA’s deeply entrenched ecosystem, AMD will need to foster greater external collaboration and demonstrate sustained software improvements.
Acquiring AI Software and Infrastructure Companies – AMD has acquired key companies to strengthen ROCm and its AI stack:
Nod.ai - October 2023 - Automating AI Model Optimization for AMD
Nod.ai specializes in compiler-based AI model automation, streamlining the deployment of AI models on AMD GPUs by eliminating the need for extensive manual tuning. One of the biggest challenges for AMD’s ROCm ecosystem is that most AI models are originally optimized for NVIDIA’s CUDA, making porting and performance tuning a time-consuming process. Nod.ai addresses this by developing tools like SHARK, an automated model optimization framework, and contributing to Torch-MLIR and IREE, open-source compiler technologies that improve ROCm’s integration with popular AI frameworks like PyTorch and TensorFlow. By reducing the friction involved in adapting AI workloads to AMD hardware, Nod.ai plays a crucial role in making ROCm a more viable alternative to CUDA.
Silo AI - August 2024 - Expanding AMD’s AI Model Ecosystem
Silo AI is Europe’s largest private AI lab, focusing on the development of open-source large language models (LLMs) specifically optimized for AMD GPUs. One of the barriers to AMD adoption in AI is the lack of pre-optimized AI models available for immediate use, as most enterprise AI workloads are built and trained on NVIDIA’s ecosystem. Silo AI addresses this gap by creating LLMs such as Poro and Viking, designed to run efficiently on AMD hardware. This acquisition ensures that developers and enterprises have high-quality, AMD-native AI models, making it easier to transition to ROCm without extensive software modifications, thereby increasing AMD’s competitiveness in AI workloads.
ZT Systems -Announced August 2024, Closing 2025 - Scaling AMD’s AI Infrastructure for Data Centers
ZT Systems specializes in AI data center infrastructure, providing high-performance computing (HPC) and AI servers designed for large-scale AI training and cloud deployment. While AMD has developed competitive AI accelerators like the MI300 series, its adoption in hyperscale AI infrastructure has been limited compared to NVIDIA’s DGX systems and H100 clusters. By acquiring ZT Systems, AMD gains a trusted data center partner capable of deploying ROCm-based AI solutions at scale, helping cloud providers and enterprises integrate AMD GPUs into their AI workflows. This acquisition strengthens AMD’s position in the AI infrastructure market, ensuring its GPUs can compete in enterprise AI and large-scale cloud deployments.
4. Key Areas Where AMD Must Improve
Expanding Compatibility & CUDA Migration

Source: https://github.com/ROCm/ROCm
ROCm’s limited Windows support remains a key barrier to adoption, restricting AMD’s reach in enterprise environments where CUDA has long been the default. Additionally, while HIP helps transition CUDA applications to AMD GPUs, the process remains complex, requiring manual tuning and debugging. To address these challenges, AMD is actively expanding Windows support and investing in HIP improvements, including acquisitions like Nod.ai to automate CUDA-to-ROCm migration. These efforts aim to make ROCm a truly viable cross-platform alternative to CUDA.
Multi-GPU Scalability with Infinity Fabric
While AMD’s Infinity Fabric offers strong interconnect bandwidth, it must improve scalability in large multi-GPU clusters to compete with NVIDIA’s NVLink. Recent developments in the MI300 series show promise, but broader adoption will require further optimization to meet the demands of large-scale AI training.
Developer Engagement and Community Ecosystem

ROCm’s long-term success depends not only on technical improvements but also on building a strong developer ecosystem. Historically, its learning curve and documentation have lagged behind CUDA, which has benefited from years of strategic investment in developer outreach. AMD has taken positive steps, last week AMD hosted its first ROCm GPU Developer/User Meetup, but continued investment in documentation, tutorials, and community engagement will be crucial.
Bonus 1: The Other AI Inference Chips
The emergence of specialized AI inference chips—such as Tesla’s Grok, Meta’s MTIA, and startups like Groq—isn’t an immediate existential threat to AMD, but it’s a serious warning sign. Meta has already deployed MTIA v2 in its data centers, yet still relies on NVIDIA for ~75% of its AI workloads, with AMD GPUs holding just a 5% share. Meanwhile, AWS and Google—instead of pivoting to AMD as an alternative—are doubling down on custom AI-centric ASICs, building vertically integrated solutions tailored to their workloads.
For now, these custom inference chips are optimized for specific, narrow tasks, meaning they’re not yet replacing GPUs entirely. But the shift is clear: cloud hyperscalers are increasingly designing their own AI accelerators instead of relying on off-the-shelf silicon. This is a problem for AMD.
• NVIDIA has built an ecosystem moat—with CUDA, TensorRT, and its Blackwell/Rubin architectures keeping customers locked in.
• AMD, by contrast, is still struggling to establish ROCm, making it harder to compete against both NVIDIA and custom silicon trends.
• If hyperscalers continue investing in in-house AI chips, AMD’s opportunity in inference could shrink, forcing it to focus on training instead—where NVIDIA already dominates.
This transition won’t happen overnight, but the long-term direction is clear. ASIC-based AI accelerators are improving rapidly:
• Groq’s deterministic AI inference enables predictable token generation, an advantage GPUs can’t easily match.
• Meta’s MTIA is already in its second generation, showing continued investment in custom silicon.
• Even NVIDIA acknowledges this shift, signaling that AI inference is moving beyond GPUs toward custom AI silicon.
If this trend accelerates, AMD could get locked out of AI inference and be left competing solely in AI training, where NVIDIA is already the dominant player. AMD has an opening today—on cost, memory, and open-source flexibility—but it’s racing against time.
Bonus 2: AMD’s CPU Strategy and the Rise of Arm
While much of the AI hardware discussion focuses on GPUs, AMD is also making significant progress in CPUs, particularly in data centers and client computing. Over the past few years, AMD has steadily gained market share from Intel, positioning itself as a serious contender in enterprise and consumer CPUs. But even as AMD grows, the x86 ecosystem as a whole faces a mounting challenge: the rise of Arm-based processors.
For decades, x86 chips from Intel and AMD have dominated computing, but Arm is emerging as a viable alternative, especially in high-performance computing (HPC) and power-efficient applications. Several factors are driving this shift:
• Major chipmakers like Qualcomm, Marvell, and MediaTek are developing highly efficient Arm-based chips, optimized for power and performance.
• Fujitsu’s Fugaku supercomputer, built on Arm, proved that non-x86 architectures can compete at the highest levels of computing.
• Arm’s advantage isn’t just in instruction set architecture (ISA)—it’s in manufacturing efficiency.
• TSMC’s fabrication process allows Arm chips to be smaller and more power-efficient.
• x86 chips, in contrast, carry decades of legacy complexity, making efficiency harder to achieve.
AMD is already adjusting its strategy. While it hasn’t entered the Arm CPU market yet, it is prioritizing power efficiency in its designs. This is evident in products like the MI300 series, a GPU-CPU hybrid optimized for AI workloads.
Although the MI300 isn’t a traditional CPU, its efficiency-first architecture suggests AMD is considering similar optimizations for future CPU designs. Additionally, with Microsoft’s exclusivity deal with Qualcomm now ended, AMD may seriously explore Arm-based CPUs to remain competitive in both data centers and client computing.
Disclaimer:
This post reflects my personal opinions and analysis only and is not financial or investment advice. I currently hold a position in AMD stock based on recent public developments discussed here over the past two weeks. Always conduct your own research before making investment decisions.